알고리즘이란?
주어진 문제를 논리적으로 해결하기 위해 필요한 절차, 방법, 명령어들을 모아놓은 것.
쉽게말해 문제를 해결할건데 이를 더 효율적으로 해결하는 것이 알고리즘이라 할 수 있겠다.
컴퓨터 알고리즘
프로그램이 어떻게 행동할지를 결정.
즉, 컴퓨터가 어떤 문제를 해결하기 위해서 컴퓨터가 이해할 수 있는 방식으로 정리되어있는 해결방법
우리가 코딩하기 편한 방식이 아니라 컴퓨터가 처리하기 편한 방식.
ex) 유튜브에서 조회수, 구독, 좋아요 순이 아니라 개개인이 선호하는 것에 맞춰서 영상을 골라주는가?
알고리즘의 필요성
점차 SW 개발의 진입장벽이 낮아지고 있는데, 이 때문에 알고리즘 실력이 점차 중요해짐.
SW 개발은 점점 대중화 되고 있지만, 알고리즘 실력은 순수 개개인의 역량에 달라지기 때문.
따라서 SW 개발자로써 성장하려면 알고리즘 공부는 필수이다.
알고리즘 공부 : 다양한 방법들을 고민해보고 분석해보면서 최적의 방법을 찾아내는 것
알고리즘 - 선형탐색
선형탐색 (Linear Search) : 순차 탐색이라고도 부르는데, 주어진 데이터 집합에서 원하는 데이터를 순차적으로 비교하면서 찾는 방법이다.
ex)
도서관에서 하버드 상위 1%의 비밀이라는 책을 찾고싶다고 가정하자.
도서관은 보통 ㄱ~ㅎ 순서로 책이 정렬되어 있다.
이때 ㄱ부터 ㅎ까지 순서대로 내가 원하는 책이 있는지 찾아가는 방법이다.
책 이름이 ㄱ 이라면 금방 찾겠지만
ㅎ이라면 끝까지 가봐야 알 수 있는 것이다.
또 다른 예를들어 [1, 12, 23, 14, 3, 7] 이라는 배열이 있다고 가정해보자.
여기서 3이라는 값을 찾으려면, 0번째 index부터 3이 있는 index까지 하나하나 비교해보면서 찾아가는 방식을 말한다.
여기서 index라는 개념을 모를 수 있는데
[a, b, c, d, e, f, g, ... , z] 라는 배열이 있다고 가정하자.
여기서 a의 index = 0, b의 index = 1, c의 index = 2, ... , z의 index = 25
terms.naver.com/entry.nhn?docId=2270439&cid=51173&categoryId=51173
선형 탐색
선형 탐색(linear search)은 순차 탐색(sequential search)이라고도 하는데, 주어진 데이터 집합에서 원하는 데이터를 처음부터 순차적으로 비교하면서 찾는 방법이다. 예를 들어 비유하면, 무작위로 모
terms.naver.com
이 링크의 내용을 토대로 알려주겠다.
아래 내용은 위 링크에 내용을 가져온 것이다.
[그림 8-4]의 데이터 집합에서 선형 탐색을 이용해 데이터 3을 탐색하는 과정을 살펴보자.

[그림 8-4] 선형 탐색을 위한 데이터 집합
① 첫 번째 데이터인 15와 찾고자 하는 3이 같은지 비교하는데, 다르므로 다음으로 이동한다.

② 두 번째 데이터인 11과 찾고자 하는 3이 같은지 비교하는데, 다르므로 다음으로 이동한다.

③ 세 번째 데이터인 1과 찾고자 하는 3이 같은지 비교하는데, 다르므로 다음으로 이동한다.

④ 네 번째 데이터인 3과 찾고자 하는 3이 같은지 비교하는데, 같으므로 원하는 데이터를 찾고 탐색을 종료한다.

만약 마지막까지 원하는 데이터를 찾지 못하면 탐색 실패로 종료한다.
알고리즘 - 이진 탐색
이진 탐색(Binary Search) : 정렬된 데이터 집합을 이분화하면서(반으로 나누면서) 탐색하는 방법이다.
ex) 도서관에서 '도깨비' 라는 책을 찾고싶다.
도서관은 보통 ㄱ ~ ㅎ 순서로 정렬되어 있다.
대충 어림잡아 ㅅ 부분을 기준으로 반으로 나누겠다.
도깨비는 ㄷ이니깐 ㅅ 이후에는 도깨비가 없을 것이다.
그러면 ㄱ~ㅂ 까지만 생각해보자.
또 대충 어림잡아 ㄹ 부분을 기준으로 반으로 나누겠다.
도깨비는 ㄷ이니깐 ㄹ 이후에는 도깨비가 없을 것이다.
그러면이제 ㄱ~ㄷ만 생각해보자.
대충 어림잡아 ㄴ 부분을 기준으로 반으로 나누겠다.
도깨비는 ㄷ이니깐 ㄴ 이후에는 도깨비가 없을 것이다.
따라서 ㄷ이 적힌 책장에서 도깨비를 찾으면 된다.
지금 예시로 설명한 과정이 이진 탐색기법의 특징이다.
terms.naver.com/entry.nhn?docId=2270440&cid=51173&categoryId=51173
이진 탐색
이진 탐색(binary search)은 정렬된 데이터 집합을 이분화하면서 탐색하는 방법이다. 예를들어 비유하면, 가나다순으로 정렬되어 있는 전화번호부에서 임의의 사람에 대한 전화번호를 찾는 경우다.
terms.naver.com
아래 내용은 위 링크에 내용을 가져온 것이다.
[그림 8-5]의 정렬된 데이터 집합에서 이진 탐색을 이용해 데이터 15를 탐색하는 과정을 살펴보자.

[그림 8-5] 이진 탐색을 위한 데이터 집합
① 중간에 위치한 데이터인 11과 찾고자 하는 15가 같은지 비교한다.

② 중간에 위치한 데이터인 11보다 찾고자 하는 데이터인 15가 크므로 중간 데이터 11의 오른쪽에 위치한 데이터들에 대해 이진 탐색을 수행한다.

③ 탐색 영역의 중간에 위치한 데이터인 17과 찾고자 하는 15가 같은지 비교한다.

④ 중간에 위치한 데이터인 17보다 찾고자 하는 데이터인 15가 작으므로 중간 데이터 17 왼쪽에 위치한 데이터들에 대해 이진 탐색을 수행한다.

⑤ 탐색 영역의 중간에 위치한 데이터인 15와 찾고자 하는 15가 같은지 비교한다. 원하는 데이터이므로 탐색을 종료한다.

우리가 코드를 짤 때 그냥 N회차까지 루프만 돌리면 되는 선형 탐색 방식이 편하지만, 컴퓨터는 처리속도가 느려진다.
우리가 코드를 짤 때, 신경써서 코드를 짜야하는 이진 탐색 방식은 우리가 불편하지만, 컴퓨터는 처리속도가 빨라진다.
알고리즘 - 정렬
정렬(Sorting) : list의 원소들을 특정순서로 정렬하는 것.
정렬은 모든 개발자가 알아야하는 가장 기본적인 알고리즘이다.
1) 선택 정렬 : 정렬되지 않은 데이터들에 대해 가장 작은 데이터를 찾아 가장 앞의 데이터와 교환해나가는 방식
terms.naver.com/entry.nhn?docId=2270435&cid=51173&categoryId=51173
선택 정렬
선택 정렬(selection sort)은 정렬되지 않은 데이터들에 대해 가장 작은 데이터를 찾아 가장 앞의 데이터와 교환해나가는 방식이다. 그러면 선택 정렬의 동작 과정을 [그림 8-1]의 데이터를 이용해서
terms.naver.com
이건 이 링크를 참고해서 이해하는게 가장 빠르다.
아래 내용은 위 링크에 내용을 가져온 것이다.

[그림 8-1] 정렬되지 않은 데이터
① 가장 작은 데이터인 1을 가장 앞에 위치한 15와 교환한다. 가장 작은 데이터가 가장 앞에 위치하게 된다.

② 첫 번째 데이터를 제외한 나머지 데이터에서 가장 작은 데이터인 3을 두 번째 데이터인 11과 교환한다.

③ 첫 번째, 두 번째 데이터를 제외한 나머지 데이터에서 가장 작은 데이터인 8을 세 번째 데이터인 15와 교환한다.

④ 첫 번째, 두 번째, 세 번째 데이터를 제외한 나머지 데이터에서 가장 작은 데이터인 11을 네 번째 데이터인 11과 교환한다. 같은 데이터이므로 위치의 변화는 없다.

⑤ 데이터들에 대한 정렬이 완료된다.

2) 삽입 정렬 : 아직 정렬되지 않은 임의의 데이터를 이미 정렬된 부분의 적절한 위치에 삽입해가며 정렬하는 방식
terms.naver.com/entry.nhn?docId=2270436&cid=51173&categoryId=51173
삽입 정렬
삽입 정렬(insertion sort)은 아직 정렬되지 않은 임의의 데이터를 이미 정렬된 부분의 적절한 위치에 삽입해 가며 정렬하는 방식이다. 그러면 삽입 정렬의 동작 과정을 [그림 8-2]의 데이터를 이용해
terms.naver.com
이것도 마찬가지로 이 링크를 통해 이해하는 것이 빠르다.
아래 내용은 위 링크에 내용을 가져온 것이다.

[그림 8-2] 정렬되지 않은 데이터
① 두 번째 데이터 11과 바로 앞에 위치한 15의 크기를 비교한다. 두 번째 데이터가 작으므로 15를 한 칸 뒤로 보내고 11을 15 앞에 위치시킨다.
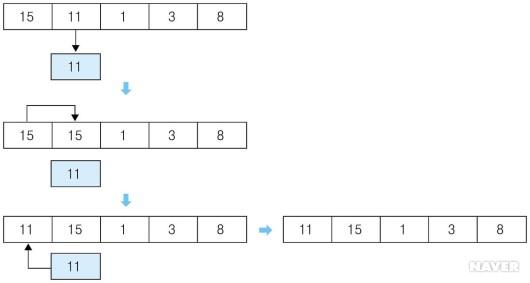
② 세 번째 데이터인 1과 앞에 위치한 11, 15의 크기를 비교한다. 1이 가장 작으므로 11과 15를 한 칸씩 뒤로 보내고 1을 가장 앞에 위치시킨다.

③ 네 번째 데이터인 3과 앞에 위치한 1, 11, 15의 크기를 비교한다. 3은 1보다 크고 11, 15보다 작으므로 11과 15를 한 칸씩 뒤로 보내고 3을 11 앞에 위치시킨다.

④ 마지막 데이터인 8과 앞에 위치한 1, 3, 11, 15의 크기를 비교한다. 1, 3보다 크고 11, 15보다 작으므로 11과 15를 한 칸씩 뒤로 보내고 8을 11 앞에 위치시킨다.

⑤ 데이터들에 대한 정렬이 완료된다.

3) 힙 정렬 : 내부 정렬 알고리즘의 하나로, 주어진 데이터들을 이진 트리로 구성하여 정렬하는 방법.
terms.naver.com/entry.nhn?docId=2455014&cid=42346&categoryId=42346
4) 합병 정렬 : 하나의 리스트를 정렬하기 위해서 해당 리스트를 n개의 서브리스트로 분할하여 각각을 정렬한 수, 정렬된 n개의 서브리스트로 합병시켜서 정렬시키는 방법.
terms.naver.com/entry.nhn?docId=187965&cid=50331&categoryId=50331
이미 정렬이 된 list를 정렬할 때는 삽입정렬이 가장 빠르다.
무작위 순서의 list를 정렬할 때는 힙 정렬이 가장 빠르다.
선택정렬과 병합정렬은 어떤 상황에서도 속도가 한결같다.
